
1. Webanwendungen
Ein Alltag ohne Webanwendungen ist heute kaum noch vorstellbar. Unzählige Anfragen werden täglich von Webservern verarbeitet und anschließend im Browser des Nutzers dargestellt. Angefangen bei der Suche nach Informationen, sozialen Netzwerken, über das Lesen von E-Mails bis hin zum Online-Shopping – all das und mehr wird mittels Webanwendungen realisiert.
In ihrer Komplexität übertreffen Webanwendungen oft die einer Desktopanwendung. Gerade die Möglichkeit, dass Webanwendungen von jedem und zur jeder Zeit nutzbar sind, machen sie zu einem sehr beliebten Angriffsziel. Kreditkartennummern und Kundendaten stehen dabei ganz oben auf dem Wunschliste der Angreifer. Etablierte Sicherheitsmaßnamen wie Firewalls und Intrusion-Detection- bzw. Prevention-Systeme bieten dagegen kaum ausreichend Schutz.
Eine gute Strategie, um eine Webanwendung bzw. den dahinter liegenden Webserver abzusichern ist eine potenzielle Schwachstelle vor einem Angreifer zu finden. Dazu eignen sich diverse Tools – sogenannte Web-Vulnerability-Scanner. Diese automatischen Scanner werden eingesetzt, um zunächst eine Grundlage zu schaffen, die wiederum als Ausgangspunkt für manuelle Tests dient. Eines dieser Tools nennt sich skipfish und wird im vorliegenden Beitrag vorgestellt.
2. skipfish
Der von Google entwickelte Schwachstellen-Scanner für Webanwendungen ist als Open Source freigegeben. Entwickelt wurde der Scanner in der Programmiersprache C und soll durch sein optimiertes HTTP Handling besonders flink arbeiten. Je nachdem, ob sich das Ziel im Internet oder lokalen LAN befindet, setzt skipfish zwischen 500 bis 2000 Anfragen ab. Auf einem lokalen Rechner sind es sogar bis zu 7000 Anfragen. Ist der Scanner einmal gestartet sucht er automatisiert nach diversen Sicherheitslücken, wie zum Beispiel Cross-Site-Scripting (XSS) oder SQL-Injections. Eine komplette Auflistung der von skipfish durchgeführten Tests findet sich in der Dokumentation.
2.1 Wie arbeitet skipfish?
Zunächst generiert skipfish durch rekursives Crawlen eine interaktive Sitemap der Webseite. Dort sind alle möglichen Links bestehend aus Dateien und Verzeichnissen hinterlegt, die während des Scan-Vorgangs untersucht werden. Interessant dabei ist das Vorgehen von skipfish, um wirklich jeden Link bzw. Datei oder Verzeichnis in der Sitemap zu indexieren. Schließlich macht ein Scan nach Sicherheitslücken nur dann Sinn, wenn auch alles geprüft wird. Um eine möglichst komplette Sitemap zu generieren setzt skipfish Brute Force Techniken und Wörterbuch-Attacken ein. Mitgeliefert werden bereits unterschiedliche Varianten von Wörterbüchern, die bekannte und oft verwendete Namen kennen. Ergänzt wird die Technik durch ein adaptives Lernverfahren. Skipfish besitzt die Fähigkeit neue Wörter und Wortkombinationen aus der Zielwebseite zu extrahieren. Die so gewonnen Daten können in einem Wörterbuch gespeichert werden und für weitere Scans genutzt werden.
3. Start des Scan-Vorgangs
Skipfish ist in der Linux Distribution Kali bereits integriert. Die Installation von weiteren Paketen ist daher nicht notwendig. Das Tool befindet sich im Verzeichnis /pentest/web/skipfish und wird über die Konsole aufgerufen. Vor dem eigentlichen Scan-Vorgang lässt sich skipfish durch diverse Optionsparameter an die Umgebung bzw. das zu scannende Ziel anpassen.
Um einen ersten Scan zu initiieren sind folgende Schritte zu empfehlen:
- cd /pentest/web/skipfish
- touch new_dict.wl
- ./skipfish -S dictionaries/minimal.wl -W new_dict-wl -o /home/skipfish http://www.example.com
Was bewirken die Optionen:
- -S: Definiert ein Wörterbuch. Auf das Wörterbuch wird nur lesend zugegriffen.
- -W: Im Gegensatz zur vorigen Option wird auf das Wörterbuch lesend und schreibend zugegriffen. Nach dem Scan wird das Wörterbuch mit neu gelernten Wörtern gefüllt.
- -o: Definiert ein Ausgabeverzeichnis für die Ergebnisse
Mit den gewählten Optionen wird aus dem minimal.wl Wörterbuch gelesen und neue Wörter werden mit der Auto-Learn Technik in das zuvor angelegte Wörterbuch new_dict.wl geschrieben. Da ansonsten keine Einschränkungen vorgenommen werden, arbeitet der Scanner im normal-dictionary-fuzzing Modus. In diesem Modus wird jedes Schlüsselwort aus dem Wörterbuch mit jeder Endung und jeder tatsächlich auf dem Webserver gefundenen Datei kombiniert. Aus den kombinierten Möglichkeiten werden im Anschluss Anfragen an den Webserver generiert, die dann alle möglichen Datei- und Verzeichnisnamen prüfen. Das ist der langsamste Modus, aber auch jener mit der höchsten Abdeckungsrate. Er eignet sich für schnell antwortende Server und kleine bis mittlere Webanwendung. Bei großen Projekten kann ein Scan-Vorgang sehr zeitintensiv sein. Je nach Größe des verwendeten Wörterbuchs und der Größe der Webanwendung ergeben sich unzählige kombinatorische Möglichkeiten. Es ist daher unmöglich vorauszusagen, wie viel Zeit eine Prüfung in Anspruch nimmt.
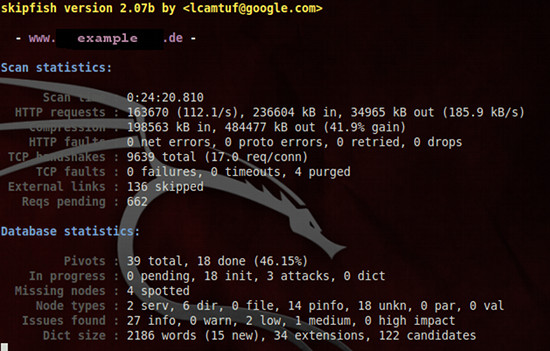
Während des Scan-Vorgangs werden kontinuierlich Statusupdates dargestellt. Je nach Umfang des ausgewählten Ziels nimmt der Scan einige Zeit in Anspruch. Zeit genug, um ein paar Optionen genauer unter die Lupe zu nehmen.
4. Optionsvielfalt von skipfish
Skipfish bietet zahlreiche Optionen, um den Scan an das Ziel anzupassen. Einige davon werden hier kurz vorgestellt. Eine Übersicht über alle Optionen erhält man mit folgendem Befehl:
./skipfish -h

4.1 Authentication und Access Optionen
Webanwendungen, die durch einen HTTP Authentifizierungsmechanismus gesichert sind oder bestimmte Cookies voraussetzen, stellen für skipfish kein Hindernis dar. Durch das Hinzufügen einer Option (-A user:pass) wird die HTTP Authentifizierung vorgenommen und der Scan kann wie gewohnt gestartet werden.
./skipfish -A user:password -S dictionaries/minimal.wl -o /home/skipfish http://www.example.com
Um die DNS-Namensauflösung zu umgehen, kann auch direkt die IP-Adresse (-F http://IP) des Ziels definiert werden. Ebenfalls sinnvoll falls das zu scannende Ziel über keinen DNS-Namen verfügt.
./skipfish -S dictionaries/minimal.wl -o /home/skipfish -F http://127.0.0.1
4.2 Crawl Scope Optionen
Der Scan-Vorgang nimmt Zeit in Anspruch. Je nach gewählter Option kann der Zeitaufwand erheblich reduziert werden. Dazu stehen verschiedene Möglichkeiten zur Verfügung. Eine davon ist das gezielte Exkludieren von Links (-X STRING). Dazu wird skipfish ein String übergeben, der von der Prüfung dann ausgeschlossen wird.
./skipfish -X /manuals -S dictionaries/minimal.wl -o /home/skipfish http://www.example.com
Umgekehrt ist dies ebenfalls möglich. Der Scan lässt sich durch die -I Option auf ein bestimmtes Verzeichnis reduzieren.
./skipfish -I http://www.example.com/dir1/ -S dictionaries/minimal.wl -o /home/skipfish http://www.example.com
Der Kuketz-Blog ist spendenfinanziert!
Unabhängig. Kritisch. Informativ. Praxisnah. Verständlich.
Die Arbeit von kuketz-blog.de wird vollständig durch Spenden unserer Leserschaft finanziert. Sei Teil unserer Community und unterstütze unsere Arbeit mit einer Spende.
4.3 Kombinationsmöglichkeiten
Die Kombination aus verschiedenen Optionen ermöglicht skipfish auf Besonderheiten von Webanwendungen und Serverkonfigurationen zu reagieren. Zu viele Request Anfragen werden von Servern manchmal als DOS Angriff interpretiert was die Blockierung der anfragenden IP-Adresse zur Folge haben kann. Ebenso kann es notwendig sein den Scan auf ein bestimmtes Verzeichnis zu reduzieren. Sei es aus Geschwindigkeitsgründen oder weil dort eine Lücke geschlossen wurde, die anschließend geprüft werden muss. Anhand von zwei Beispielen wird im Folgenden die Kombination aus verschiedenen skipfish Optionsparametern dargestellt.
./skipfish -r 5000 -m 5 -L -o output_dir -b ie http://www.example.com/
- -r 5000: Beschränkung der maximalen Anzahl von Requests auf 5000 (Standard: 100000000)
- -m 5: Es werden maximal 5 Verbindungen zum Ziel initiiert.
- -L: Die Auto-Learn Funktion wird abgeschaltet.
- -b IE: Gegenüber dem Webserver gibt sich skipfish als Internet Explorer aus.
./skipfish -S dictionaries/complete.wl -P -I http://www.example.com/dir1/ -o output_dir -t 5 http://www.example.com/dir1/
- -P: Vom Ziel werden keine HTML Links extrahiert
- -I: Das Ziel wird auf ein bestimmtes Verzeichnis eingeschränkt
- -t 5: Der Request-Timeout wird auf 5 Sekunden reduziert (Standard: 20 Sekunden)
5. Ergebnisse des Scan-Vorgangs
Der kurz Einblick in die Optionsvielfalt von skipfish sollte einen Eindruck über die Möglichkeiten des Tools vermitteln. Sobald der zuvor angestoßene Scan-Vorgang abgeschlossen ist, wird dies auf der Konsole ausgegeben. Skipfish informiert über die Anzahl der neu gelernten Wörter und wie viele Knoten vom Crawler verfolgt wurden. Alle Ergebnisse werden im Ordner /home/skipfish/ zusammengefasst.

Das Resultat liegt im HTML-Format vor. Die Meldungen werden übersichtlich untereinander dargestellt und können mit einem Mausklick expandiert werden, um detaillierte Informationen abzurufen. Eine Gruppierung des Risikos in Kombination mit allen relevanten Informationen hilft bei der Bewertung von potenziellen Schwachstellen.
Skipfish gruppiert die Meldungen des Scan-Vorgangs wie folgt:
- High risk flaws – Kann zur Kompromittierung des Systems führen
- Medium risk flaws – Kann zur Veränderung von Informationen / Daten führen
- Low risk issues – Eingeschränkte Auswirkungen
- Internal warnings – Warnungen
- Non-specific informational entries
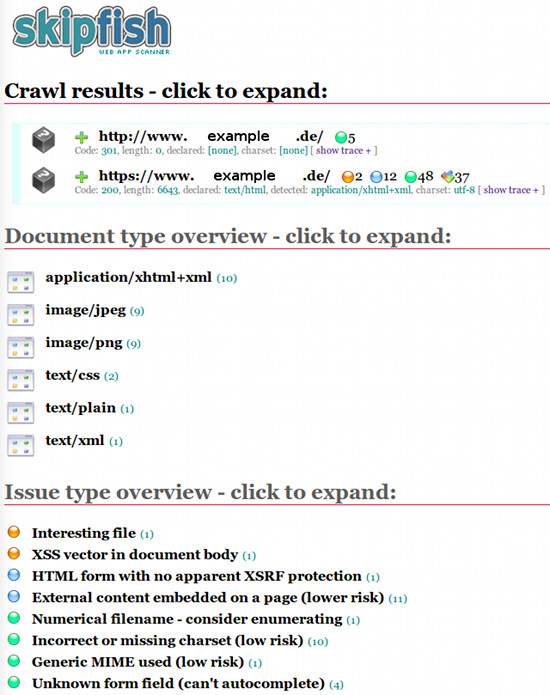
Skipfish »überflutet« den Anwender mit vielen Informationen. Darunter sind grundsätzlich auch etliche Fehlalarme. Hier steht der Tester in der Verantwortung. Bei der Ergebnissichtung müssen tatsächliche Alarme von Falschmeldungen getrennt werden, was bei der Masse von Meldungen mitunter einige Zeit in Anspruch nimmt.
Interessant sind Informationen, die auf externe URL-Redirectors hinweisen. Dahinter kann sich manipulierter Quellcode verbergen, der gerne von Spammern eingesetzt wird, um Besucher auf andere Webseiten umzuleiten. URL-Redirectors können also ein Indiz für kompromittierten Quellcode darstellen und sollten untersucht werden.
Ein Beispiel:

Skipfish weist im Ergebnis auf eine externe Verknüpfung hin, die im Quellcode implementiert wurde. Im Beispiel stellt dies allerdings keine Gefahr dar. Es handelt sich um Matomo, einem Tool zur Webanalyse. Es wird vom Betreiber eingesetzt, um beispielsweise die Besucherzahlen oder Verweildauern auf Seiten zu messen. Skipfish schlägt dennoch Alarm, da sich die Auswertungskomponente von Matomo auf einer anderen Domäne befindet.
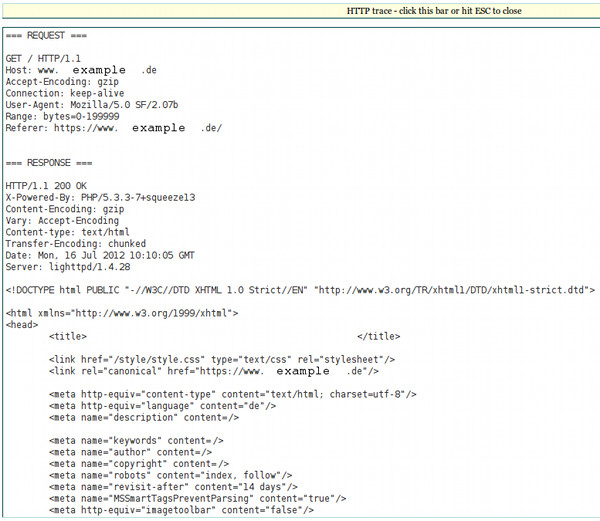
Um genau Informationen zu einer potenzielle Schwachstelle zu erhalten, reicht ein Klick auf show trace am Ende der Zeile. Mit Hilfe der dargestellten Informationen lässt sich die Position der Schwachstelle im Quelltext meist schnell lokalisieren.
6. Fazit
Für den »schnellen Scan« eignet sich skipfish eher nicht. Generell benötigt ein Scan etliche Stunden bis ein Ergebnis vorliegt. Im Anschluss wird der Anwender dann mit vielen Informationen überflutet, die es gilt korrekt zu interpretieren. Dank der verwendeten Heuristik gekoppelt mit dem selbstlernenden Algorithmus ist die Bedienung grundsätzlich sehr einfach. In Kombination mit diversen Optionen, lässt sich der Scan je nach Ziel und Zweck variieren. Mit der Detail-Ansicht lassen sich potenzielle Schwachstellen genau lokalisieren und anschließend korrigieren.
Alleine auf skipfish sollte man sich beim Auffinden von Schwachstellen in Webanwendung allerdings nicht verlassen. Aus rein strategischen Gründen und mit dem Hintergedanken, dass skipfish nicht alle Schwachstellen finden kann bzw. darauf ausgelegt ist, sollten immer mehrere Tools kombiniert werden. Dazu eignen sich weitere Web-Vulnerability-Scanner, wie beispielsweise w3af oder Nikito. Erst eine Kombination aus mehreren Tools und Techniken vervollständigen eine Schwachstellen-Analyse einer Webanwendung.
Bildquellen:
skipfish: https://code.google.com/archive/p/skipfish/
Über den Autor | Kuketz

In meiner freiberuflichen Tätigkeit als Pentester / Sicherheitsforscher (Kuketz IT-Security) schlüpfe ich in die Rolle eines »Hackers« und suche nach Schwachstellen in IT-Systemen, Webanwendungen und Apps (Android, iOS). Des Weiteren bin ich Lehrbeauftragter für IT-Sicherheit an der Dualen Hochschule Karlsruhe, sensibilisiere Menschen in Workshops und Schulungen für Sicherheit und Datenschutz und bin unter anderem auch als Autor für die Computerzeitschrift c’t tätig.
Der Kuketz-Blog bzw. meine Person ist regelmäßig in den Medien (heise online, Spiegel Online, Süddeutsche Zeitung etc.) präsent.
 Unterstützen
Unterstützen
Die Arbeit von kuketz-blog.de wird zu 100% durch Spenden unserer Leserinnen und Leser finanziert. Werde Teil dieser Community und unterstütze auch du unsere Arbeit mit deiner Spende.
Wenn du über aktuelle Beiträge informiert werden möchtest, hast du verschiedene Möglichkeiten, dem Blog zu folgen:

Risiko Webanwendung – Sicherheit von Webanwendungen Teil1

Klassifizierungsmodell – Sicherheit von Webanwendungen Teil2

Angriffstechniken – Sicherheit von Webanwendungen Teil3

nmap: Systeme auf offene Ports scannen

Abschließender Hinweis
Blog-Beiträge erheben nicht den Anspruch auf ständige Aktualität und Richtigkeit wie Lexikoneinträge (z.B. Wikipedia), sondern beziehen sich wie Zeitungsartikel auf den Informationsstand zum Zeitpunkt des Redaktionsschlusses.Kritik, Anregungen oder Korrekturvorschläge zu den Beiträgen nehme ich gerne per E-Mail entgegen.